We’ll just ignore I haven’t posted in ages. Nothing to see here.
So…, wow! A.I. is now everywhere you look. It’s getting jammed down our throats at every opportunity. Don’t get me wrong. I’m a big user and have been since it became self aware useful so probably starting around early 2023. Its only been 3 years and the improvements are staggering. I’ve programmed A.I. since 2008 so I think I’m in a fairly good position to judge the state of A.I. and it’s usefulness.
There’s a work transformation happening right now, old methods are rapidly being replaced, new rules being written and being re-written just weeks later. Everything is moving so fast it’s worse than the jokes about new javascript framework release schedule.


What’s current this month, probably wont be current next month.
But the most noticeable change is the roles people will play in this brave new world. Anyone that sits at a keyboard, your role will change dramatically, mostly for the better, with some caveats, and either you’re on board, riding the wave or you’ll be rolled and left drowning in a tsunami of new technologies.
Nowhere is this more rapid than the role of developer. A.I. has brought about a massive change to these roles in a matter of months that raises a lot of still unanswered questions, which I’ll get to in a moment. We’re heading into truly unchartered territory.
Questions, questions, questions
The first hurdle that, as a developer I think you have to climb is that you now have to recognize your workflow is fundamentally changing. The developers that are thriving are the ones that have embraced this new world order. They’re not necessarily the ‘best’ developers anymore, but the best at realising that the role now revolves around organising context, prompt engineering and how to look over what the AI has generated. For now.
And here’s the first of the questions that are arising. When the AI is better at writing code than you are, is it necessary to review the code with a fine toothed comb? Currently, yes, but it won’t be long before that’s an unnecessary time suck. Literally, give it a month. Personally I won’t miss that, but then I’m a lazy developer.
This brings into focus a second question. Since the model knows all the languages better than you, you can choose to create the application in the language best suited to the application, rather than the language you know the best. Want to write a mobile app? Ignore all the cross platform fluff & go native. Choose Swift for Apple and Java for Android without knowing either. Yes, we’ve tried that too.
So, third question, if you choose a language that you don’t know, how will you review the code effectively? What will it mean to enforce coding standards if no one is going to read the code?
And, if you choose a language that you do know, have you chosen a sub optimal solution (according to the model), effectively nobbling the application just so you can review the code?
A fourth, a far reaching related question. What does it mean now to learn a new development skill?
I used to want to be awesome at C# & .net coding, staying up to date with the latest language features, frameworks & tools. I thought that would bring me higher salaries and make me more ‘desirable’ on the employment market. But, is this really necessary any more beyond what I already know? Is there still any benefit knowing the difference between covariance and contravariance, or being able to apply S.O.L.I.D. principles, or even demonstrate this level of knowledge?
It used to be that technical expertise played a large part in securing a well paid role. What if that doesn’t matter as much? Will this be now measured on your English skills, how well you write a PRD, or how well you can prompt an AI compared to the other job candidates?
Although 47% of developers use AI daily according to the last Stack Overflow 2025 survey there are over half that use it weekly or less and 16% that don’t plan to use it at all. Is this a mistake? Some employers have mandated A.I. usage, so where will that leave developers that refuse to use A.I. ?
A story that leads to an application & a serious test.
Back in 2013 I was diagnosed with Relapsing remitting Multiple Sclerosis. I started with numb legs, I struggled to walk, had terrible balance and lost my eyesight to the point I was effectively blind.
On visiting the hospital, I was seen by Professor Basil Sharrack where I volunteered for a 10y experimental drug trial. This was deemed to have failed in 2016 as I was still having relapses , so I was offered a pioneering stem cell transplant as treatment. I was patient #16 (in the world!) to have this treatment for MS at the Hallamshire hospital and was told that at the rate of my disease progression I would be in a wheel chair within 5 years, if I didn’t do something.
Of course I said yes. Three months in hospital, intense chemo-therapy and one pluripotent stem cell transplant later, and I’ve had no relapses since. Its been effectively a cure for a currently incurable disease. Go Science!. Although, Chemo – 1 Star – Would NOT buy again.
However, my eyesight still had minor issues. The optic neuritis I suffered in 2013 had damaged my retina where I have a remaining patch of missing vision. Its a thumbnail sized patch at arms length in my peripheral vision, so not a great loss, and it causes no problems day to day.
When I was recovering the first time, my sight was like looking through a leopard print pattern. Not that you notice because your brain fills in the missing pieces of vision so you don’t realise you’re missing anything. This is known as “perceptual completion”, it’s the reason you don’t have a “hole” at the point the optic nerve goes exits your retina – the “optic disc”. Everyone has this blind spot. I thought, wonder if I could map my missing vision, and track the changes as it heals?
Cue the Meyesight app.
When I want to learn something new, I find its best to have a ‘meaty’ application to play with. I find the typical ToDo list, twee-apps or single page blog post explainers a waste of time.
So, of course being a developer at heart I wrote an app to ‘map’ my missing vision. Enter Meyesight. This has been my go to app to re-write when I want to learn anything new. New framework? Rewrite Meyesight. New interesting language? Rewrite Meyesight.
The app itself consisted of the typical full stack, front end, back end & database, so I could use the language & associated framework as a learning platform.
It consists of a vision mapping screen where a cross is placed in the centre of the screen as a focal point. Whilst you concentrate on the cross with one eye, a dot scans the screen, left to right, top to bottom, and when the dot disappears you press the space bar to record the missing vision location, releasing the space bar when the dot re-appears. Do this for both eyes and you effectively have a ‘map’ of your visual field.
Meyesight Dashboard:

Introducing A.I. to the app.
Already having a deep love of A.I & data science, I was looking for some way of adding an A.I. feature to a) make the app more useful and b) make it more complex to implement, since re-implementations were really just a language mapping exercises, and while loops look the same in any language.
After searching around I came across this paper on using neural networks, specifically a Gradient Class Activation Mapping network for medical imaging.
Thinking this might have some utility for mapping the changes in the missing regions of sight over time in the same way the paper authors used it to map changes in tumour growth, I added a Grad-CAM neural network to help map any disease progression. I reasoned that the visual field patches changed in similar ways to how the tumours in their sample medical images changed, so it might be useful. Even if it proved not to be useful medically, it was definitely useful as a learning exercise, which was the main point after all!
Originally written from scratch in python, it took me nearly 3 months just for the initial implementation. So, in total the first incarnation of the Meyesight App to include A.I. took about 5 months. This will be relevant later.
Example heatmap:

In total, the app’s been re-written 4 times since 2014 – WPF, C# + Asp.Net MVC, Elixir + Phoenix, finally React. The addition of the neural network. was around 2018. Each re-write before this had taken at least 3 months. Remember speed wasn’t the point here, its a learning exercise.
Agentic coding has joined the chat.
Now, lets be perfectly clear, I don’t want to give up coding. I’ve been coding since 1981, starting with writing commercial games in 6502. I have history. A LOT of history. So I fully understand where the 16% of Stack overflow responses come from. I have forty years of hard won knowledge that I’d like to preserve thankyou very much. However, I also realise times change. A co-worker put it best in a recent meeting when told we were to use A.I. for development when he stated “Why? Am I not good enough?”. I think that sentiment rings loud. He’s probably the best developer I know. He’s already 10x, even without A.I.
Warning : skill deprecation approaching.
First, I’ll use the example of originally writing a games 3d rendering using the 80×86 CPUs to do polygon fills, way back in the days when we wrote games mostly in x86 assembly. GPUs on video cards weren’t around, and the Voodoo card wasn’t even a twinkle in 3Dfx’s eye until 1996. We used to optimise the code for the polygon fills using tools like Intels V-Tune to wring out every cycle the CPU could muster. Remember, CPU speeds were measured in Mhz – the 16bit 8086 (1978) was just 5Mhz & even the 32bit 80386 was clocked at a measly 12Mhz. Getting speed out of these for polygon filling was a hard won skill and gave any brave developer PTSD for years. Performance Tuning Stress Disorder is a real thing.
Then came along the C compilers. Suddenly optimisers on compilers like Wacom C used to do CPU pipeline optimisations for us. Boom that skill was now redundant.
We used to write our own memory management systems in assembly. Then came C & C++ with their fancy malloc and new. Boom, that skill was redundant. We used to be responsible for carefully managing the allocation & de-allocations in C & C++ constructors & destructors, then came Managed code like C#. Boom, that skill was now redundant.
There’s a pattern emerging here.
Developer knowledge gets deprecated when new technologies appear. No big deal, there’s always the new technology to become competent with, and loss of obsolete skills is inevitable. But the underlying knowledge of how memory allocation worked is still useful, because even though C# manages the memory, you’ll still need to understand what’s going on inside if you ever need to ‘tune’ what’s happening or fix leaks. Yes, it still leaks.
It wasn’t just computers, the same happened in other areas. Take Rally cars for example. I had a Subaru WRX STi TypeRA and later a Mitsubishi EVO FQ330 around the time Richard Burns and Petter Solberg were WRC drivers for Subaru. In the mid 90’s the Impreza WRX STI’s Driver Controlled Centre Differential (DCCD) system was upgraded with a yaw-rate sensor to automatically adjust torque distribution, making the STI “push harder” through turns without demanding as much expertise from the driver. The Lancer EVO IV introduced the Mitsubishi Active Yaw Control (AYC) system, developed from rally experience to actively manage the car’s rotation in corners. Mitsubishi said – AYC balances the lateral forces between front and rear to “maximize cornering performance,” enhancing or correcting understeer and oversteer as needed.
Boom, an average driver like me could suddenly drive a little more like Petter Solberg and get way better track times. They’d effectively “put the rally drivers knowledge into the cars driver aids.”


Ok, AYC didn’t quite save me from aquaplaning on all 4 wheels. Generally however, driving aids make the cars safer, but also lower the skill level required to achieve better results on track days.
These are all examples of the democratisation of a complex skill, lowering the barrier to entry, so effectively lowering the bar.
But this time, A.I. & LLMs are different.
Lets go back for another driving example. Imagine if Mercedes took Lewis Hamilton to one side and said, “hey Lewis – we’ve put an AI into your Mercedes F1 car. It’s now autonomous and will drive round any track faster than you. Thing is, we haven’t given it vision yet, so you need to sit in the drivers seat and describe the track to the car”.
I’m guessing Lewis lives for driving. You don’t get to that level by eating donuts and watching re-runs of Love Island. But you’ve removed that fundamental reason Lewis loves driving. He’s spent many years honing that skillset to an extreme level. Hello, role insecurity, loss of identity, anxiety and reduced self esteem. “Lewis, you’re currently the #1 track describer in Formula 1!” Kind of loses the prestige a bit, but it would mean I’m in with a chance at competing against Lewis, as would anyone else that can describe the formula 1 tracks in detail. See what’s happening here?
A.I. isn’t just deprecating the last technology like before. Replacing the old tech with something new yet still technical that requires skill to learn & understand, its effectively removing the need for that specialisation, that level of understanding. Mercedes wouldn’t need Lewis when any of the pit hands can also describe the track in equal detail.
I think this will also happen to developers, or any tech person for that matter, especially those that have dedicated most of their working lives to their craft. Like me, and many others from my era. Homogenized skill sets are on the horizon.
Just like Lewis probably lives for driving, a developers’ identity is tied to problem-solving. If AI shifts them into passive roles, that can erode purpose and confidence. I’m not sure everyone will enjoy the shift from from creator & problem solver to overseer. That’s really a profound mental shift.
The Mercedes example is a direct analogy of what companies are expecting of developers right now. Well, almost. As professionals, we’re still expected to ‘review’ the code A.I. produces, in the same way Mercedes would want Lewis to describe the track. Maybe have a second person do a Track description PR and check his description’s good enough to win. But think back 6 months ago, AI could barely produce code that compiled. Give it another 6 months, we won’t need to review what it produces either.
Personally, I think we’re probably already there. I’ll show you why shortly.
Voices in the wild.
It’s not just me thinking about the erosion of skills and lower perceived competency required for complex cerebral work.
In an article from FastCompany, analysts have observed that AI “empowers us to do things that once required years of training by democratising skills across the workforce.”
In another article from Maggie Smith of the North Carolina Department of Commerce, she notes “that generative AI can boost productivity and ‘democratization of skills,’ allowing workers to accomplish complex tasks without deep specialized expertise”. Figure 1 of her article below, shows the white-collar jobs exposed to A.I.:

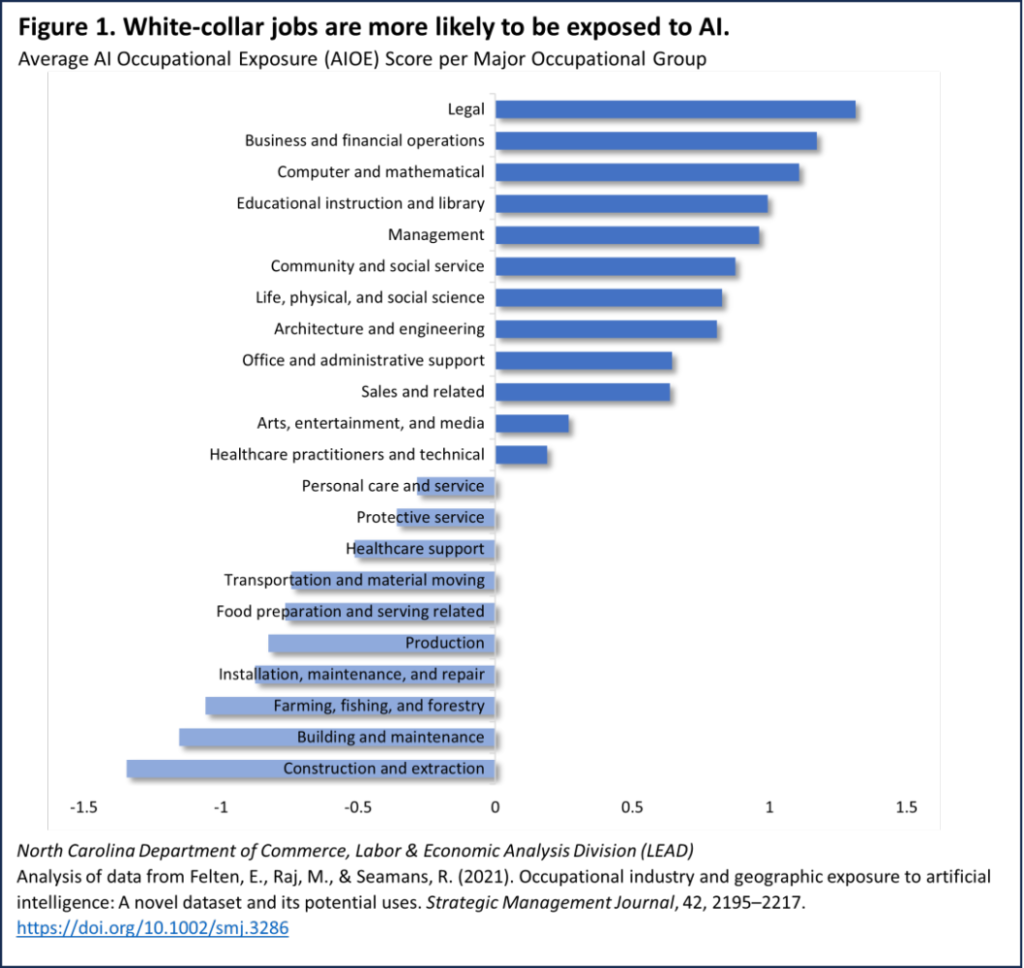
Notice the top half? This is validated by Geoffrey Hinton, the Godfather of A.I., in a recent interview on Steven Bartlett’s podcast Diary of a CEO when asked
SB: “What would you say to people about their career prospects in a world of super intelligence?”
GH: “Learn to be a plumber.”
Geoffrey talking about a move from the top half to the bottom half, this is borne out by Maggie Smith’s article’s figure above. Here’s another paper from Microsoft Research, Measuring the Occupational Implications of Generative AI where we can see a similar story emerge.
Physical jobs are safest for now. But then China has just hosted the Humanoid Games where the over 500 robots from 16 countries competed against each other for speed, agility & endurance. One highlight – the Unitree H1 ran the 1500m faster than humans, setting a new, well, artificial world record. Yes, there’s a lot of comedy fails but we’re at the very beginning of humanoid robotics. Do we need a new category for the Olympics for when things improve?
I remember seeing a tweet where someone said “I want the robots to to do the housework and the laundry, not create art and music”. At least the housework looks like that’s covered.
Back to Meysight.
To demonstrate why I think we’re almost there & not actually having to review code, I chose another learning exercise. I re-wrote Meyesight, but going 100% all in on AI. I thought “how far can I push Claude here” i.e.
I gave up coding on this project to see if it would work & what I felt like after the experience.
I purposely wanted to see if I would have to write any code, any tests, or fix any bugs.
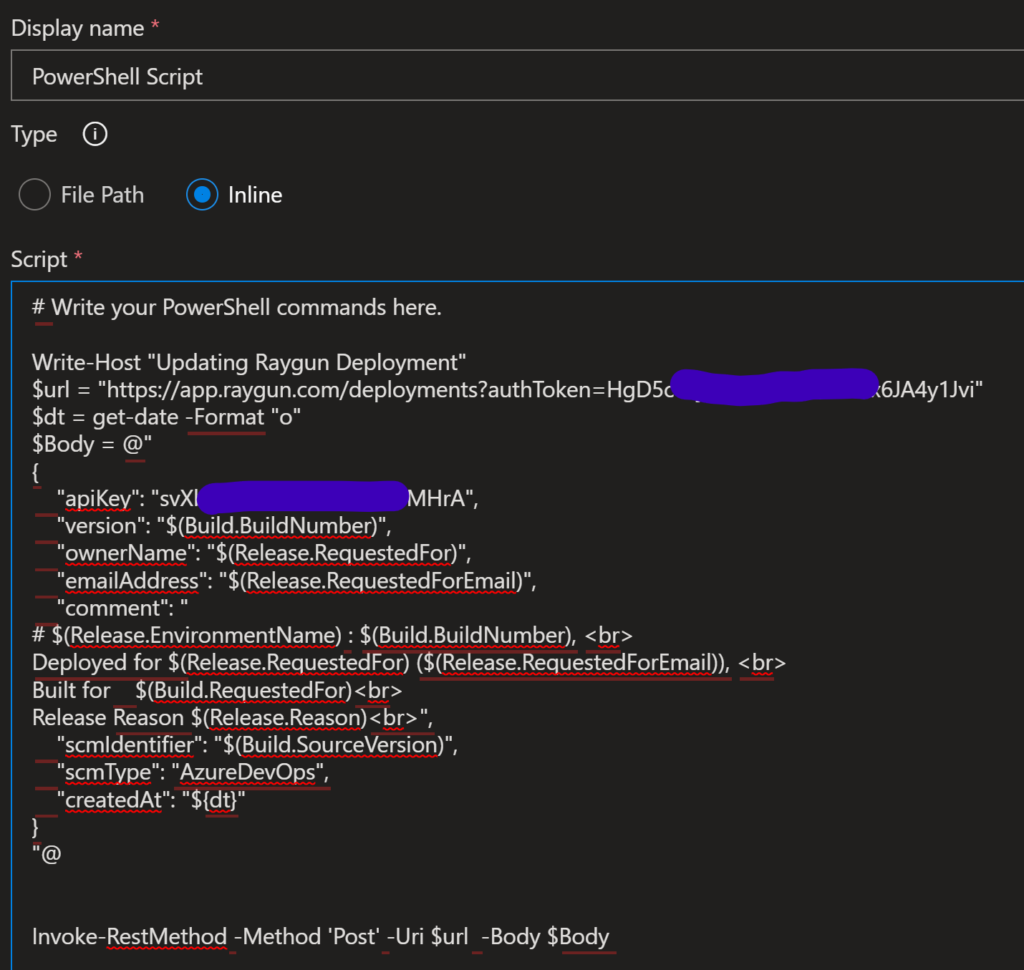
I spent about 6 hours working with ChatGPT5 then Anthropic’s Claude, writing a really comprehensive Product Requirements Document to hand to GitHub’s Copilot in VSCode. I described the application in as much detail as possible. I asked Chat GPT 5 what was missing and if it could think of any features I hadn’t described adequately for implementation by Copilot. I went round in circles for hours, answering CGPT5’s & Claudes questions, editing the document, asking if it was ready for implementation again, and again, and again.
Eventually, passing the Chat GPT document to Copilot ( & iterating it further with Claude Sonnet ), it said the document was good to go :

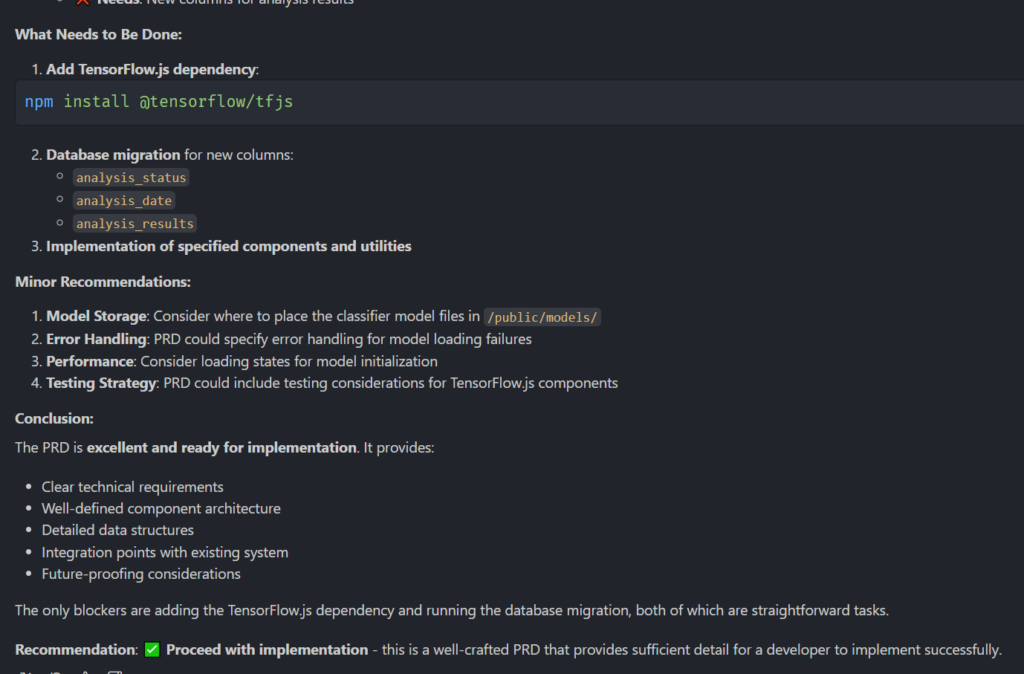
There you have it. “The PRD is excellent and ready for implementation“.
Point to note, Claude Sonnet was way better than ChatGPT at seeing the missing pieces of the PRD to actually produce an implementable document. CGPT left a lot of holes but thought it was complete.
So, I attended to the 4 minor recommendations and told Copilot to add Tensorflow, do the migrations and implement any specified components and utilities. The test was to see if I could stay 100% in the Copilot chat window, and never touch the editor side of VSCode.
Spoiler: I did.
Not only did it implement the Database schema using migrations for Supabase, it also wrote the entire Grad-CAM neural network in Javascript, alongside the entire front end in React using Tailwind for the CSS & layouts. It designed the screen layouts and even added features I didn’t request like little images on the lists :
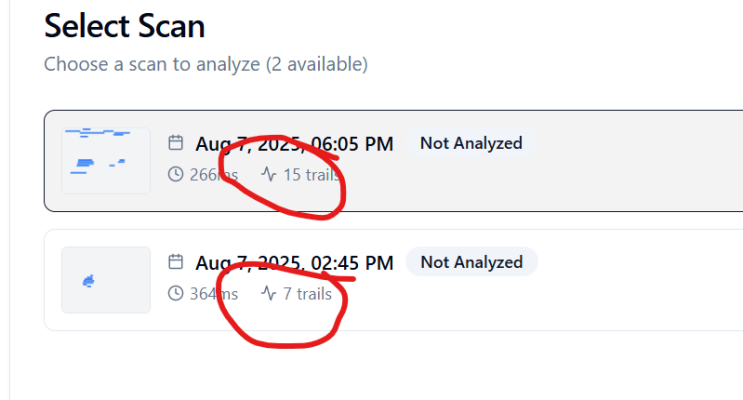

I didn’t ask for the any of those little icons. Or the thumbnail. Or the list layout, or the Analysis status. The model really went over and above what I’d asked for, and completely nailed the layout. All the screen shots above we entirely Claude generated layouts. More importantly, not a single compilation error, or non-working page. Claude Sonnet 4 is damned impressive. If this had been any of the OpenAI models I doubt it would have even compiled. Its important to note that I think the only reason it did such a good job at implementation is because the initial PRD was so detailed, it was practically a rewrite to start with.
There were a couple of minor issues on the calibration page, where the app measures your reaction time (hence the 266ms & 364ms labels above) so that it can semi-reliably offset the scan tracks when the dot disappears offsetting when you press the space bar to record. But they were truly superficial, and I still never looked at the code. I described the problem in as much detail as possible and let it find the problem & fix the code. I think it took 4 or 5 attempts to get it working how I wanted.
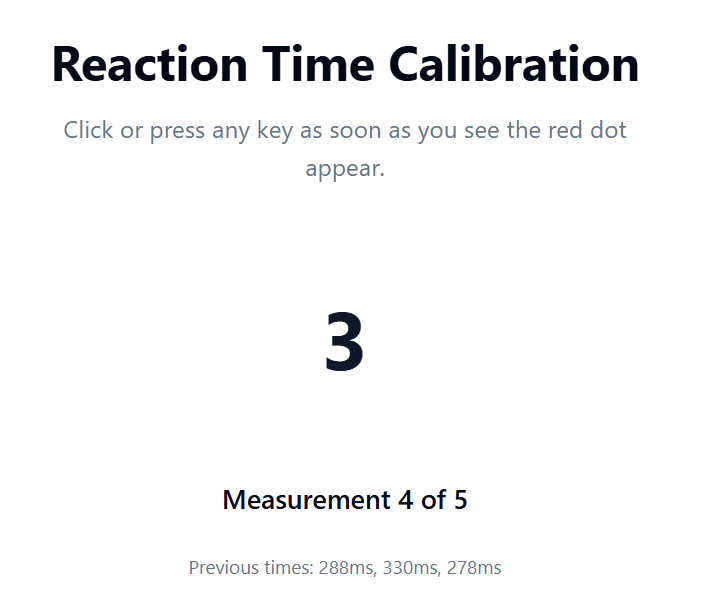

Do I need to look at the code? I don’t think so. It works 100% – it also did a fantastic job of creating comprehensive unit tests, validating that the code works at a fundamental level.:


Would I trust it to write a Netflix scale app. No of course not. Small scale commercial code? Yes. Test apps & POC work. Absolutely.
Turns out I’m not the only person that’s gone 100% hands off, accepting what the LLM generates. Mirek Stanek of Papaya Global has just done the same thing. Using AI to generate 100k lines of code for a production level app. He also explains they there’s a real danger of companies not capitalising on this shift. Smart guy.
At the current rate of progress, give it a year or two before the other scale apps are 100% AI generated, especially since AlphaGo have already achieved what was on the AI-2027 roadmap for June 2028 almost 3 years ahead of that schedule. Don’t read either of those if thinking about Skynet gives you anxiety. I’m serious. Don’t do it.
The TL;DRl of the AlphaGo paper is that they’ve created an AI that’s better at writing AI than humans. AI is no longer constrained by human thought, but only by compute power and electricity. And we know how that can scale.
So, why is context the new black?
Back to the title of this article. Its taken a while, We’ve laid the groundwork, but we’ve got here so thanks for making it this far!
CONTEXT IS EVERYTHING. ORGANISE IT LIKE YOUR LIFE – AND YOUR JOB – DEPENDS ON IT.
If I could put that in a larger font I would. Spending an entire day on the Meyesight PRD is the only reason it was implemented without a hitch.
How did I feel?
Not as bad as I expected, though this may be the honeymoon-amazement-that-it-actually-worked period. I dislike web development, so having something else worry about CSS and layout is something I can totally get behind!
Was I bored? YES, very.
Did I have faith it would work? NO.
But then I’d only really experienced OpenAI’s models, or Qwen Coder models running locally, using code fragments & cut-n-paste, so nothing this complex to measure against.
Everything the model does is only as good as the context you give it. If it makes an error, its because your context wasn’t good enough. Remember this thing can now code better than you, faster than you, and anyone you know, like I said if you don’t think that’s the case yet, give it a few months. Meyesight has already proven this for me. But, YMMV.
Realize that context management is now your CORE ENGINEERING SKILL. Not coding, not architecture, not testing, not design, not UX, not anything specific. The model will replace all these given the correct context. I have receipts. Poor old Stack Overflow is living proof of this shift happening in real time – the number of questions asked is now at 2009 levels and still trending downwards. In his blog article on The decline of Stack Overflow. Eric Holscher points out the effect that Chat GPT has had on its decline since 2022. It’s a little ironic that he sites there’s still need for a canonical resource for reference information, but then as the creator of Read The Docs he has a vested interest in maintaining the status quo.
Sorry, Eric I think you’re next.
Of course there’s still the requirement that a developer / architect / designer / tech person, works with the LLM since they’ll have all the requisite knowledge about what they want the LLM to create. Context creation still needs a driver. Mercedes will still need a Lewis. Having a skilled driver is still important.
As a developer, the biggest blocker was your typing speed. Now the biggest blocker is your ability to give clear, concise, explicit requirements to the model. If anything it’s become more cerebral, not less. Awesome-Copilot is a github repository brimming with pre built context documents for various languages and chatmodes to configure the agents. Its a good starting point to get a feel for required context building.
So, CONTEXT IS EVERYTHING. I think I mentioned that in passing.
Beneficial or not?
Is the A.I. change beneficial to us developers? Yes, I think so. It’s multiplied my work capacity ten-fold. And that’s great, but here’s where the managers and companies need to listen up, it doesn’t mean features can be produced 10 times faster. For that, every part of the pipeline has to move at 10x the rate. And that’s just not feasible.
As a single developer, working in isolation, yes, you can go 10x. Implementing Meyesight, took ~5 months before, now that’s shrunk down to 1-2 days with the caveat that I already had an intimate understanding of what was required having done this 4 times before. If I was generating the PRD from scratch, I think a week would have been adequate. If others were involved then everyone would have to move at the same pace, and as everyone knows adding people to a team doesn’t necessarily increase velocity as the lines of communication increase. Plus, the power dimension is always vertical and a choke point. Well orchestrated, flat hierarchical , diverse, generalist teams will be the ones that benefit the most from A.I. but this is the only pipeline arrangement that can move in multiples.
Amish agents!
To truly get the whole 10x productivity, the typical model of the Amish barn-raising is a good example to emulate. Check the Harrison Ford movie Witness, where the Amish raise a barn in a single day. Its remarkable that there were no managers, no team leads, no leaders leading the leadership. No debate over the design, no discussion on who does what. Just perfect harmony until the job is done. This is what I experienced working with the A.I. agents re-creating Meyesight. Although I had the initial requirement, I asked it what was missing, what could be better, what should be left out, what screens we’d need. I deferred ownership and we worked together, in equal partnership until the task was complete. And it worked perfectly. This was literally the definition of Utopian Teamwork. An Amish barn raising on my desktop. Me totally embracing A.I.
It took a lot to cope with the realisation and defer to the agent because most of the time, it really does know better. Again, if you think its not there yet, give it a couple of months.
Job safety
Here’s a quote from Scott Hanselman in a fireside chat, “A.I. won’t make you redundant, corporate greed will.”. I think he’s right and there are many purists arguing that democratization of expertise will commodify work making outputs interchangeable and devoid of personal touch. For example in a recent DevRev article – Preserving craft in the era of AI, they explain in detail how the industrial revolution replaced artisans with standardised production. Maybe artisanal code will come round to be a selling point, like hand built cars or watches. “Coded by humans” might be as sought after as an Aston Martin or a Breitling Navitimer. I know where there are at least 16% of developers down with that.
Personally, I’m very grateful to work with a small team of developers for a company that recognises that A.I. is a productivity boost for developers, not a replacement. As Scott said in the same podcast, “Humans are the force multiplier of A.I.“, I think our company recognises that.
Long may that continue.
I hope you got some value out of this article, all comments welcome. Thanks for reading, any questions, please reach out.
PS. Bonus points if you recognise the equations in the title image 😉 NO FEEDING IT TO CGPT!
PPS. 0% of this article is written by AI. That’s why its full of bad grammar, spelling mistakes and missing punctuation. No A.I. is that bad. But I AM, and I’ll own it.
Now, a polite request, can you help me?
My wife is wanting to change careers to become a QA. She’s done a year of voluntary testing, mostly manual testing with some entry level automation using Postman for API tests. She also used Azure Devops TestPlans, Confluence and other tools relevant to the role.
She’s also currently working towards her ISTQB. And because I’m all in on A.I. I’ve taught her how to 10x her test generation using VSCode & Playwright MCP. She’s A.I. & automation ready!
She’s happy to join at the very, very bottom, in an entry level position at a junior level or even apprentice if it gets her into the industry. Ideally remote or hybrid with a local commute. We realize just how scarce these roles are. She also has me behind her, mentoring her & keeping her ready for her new career path with all the latest advances!